

Twenty years ago, the TOP500 list was dominated by vector processing supercomputers equipped with up to a thousand processing units. Later on, these machines were replaced by clusters for massively parallel computing, which soon dominated the list, and gave rise to distributed computing. The first clusters used dedicated single-core processors per compute node, but soon, additional processors were placed on the node requiring the sharing of memory. The capabilities of these shared-memory parallel machines heralded a sea change towards multicore processors that requires robust and adequate algorithms in all kinds of computing applications. Looking at the TOP500 list today, we can observe that the majority of the clusters are made up of a very large number of compute nodes with multiple sockets and up to eight cores per multicore processor in each socket. The techniques for computing in parallel for shared memory computers differ from those used when computing on a cluster with distributed memory. This demands a mixed (hybrid) approach for efficient parallel computations.
Shared and Distributed Memory
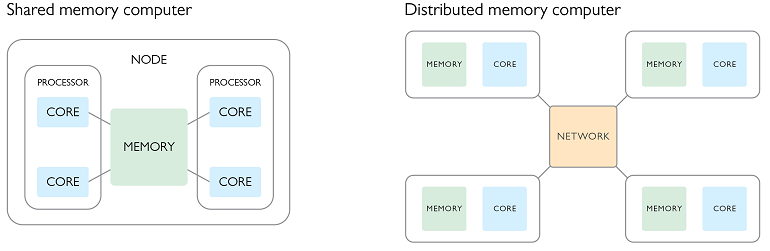
Parallel computing basically consists of two different classical set-ups: shared memory and distributed memory. There are many structural differences between these two approaches, even if the goal is ultimately the same — to perform faster and larger computations by utilizing parallel hardware. (Tip: The tutorial from the Lawrence Livermore National Laboratory provides a detailed introduction to parallel computations.)
The name of each method expresses the basic difference between the two. In the case of shared memory, the distributed parts of the overall program that are running in parallel all share the same memory space. This provides speed when passing data between the cores and processors. Yet, the major drawback of shared memory computing is that the computing resources on a shared memory node are limited. Additional resources cannot be added when the problem size is increased or more cores should be used to reduce the number of computations per core. Shared memory computing does not scale well.
In distributed memory computing, the memory is not shared but instead is distributed among several parallel processes. These processes have to explicitly communicate with each other by sending “messages”. As a consequence, communication and synchronization consumes additional time and the amount of communication should be minimized by exploiting data locality and improved algorithms. The big advantage of distributed memory computing is that it typically scales well as additional resources (nodes, and hence cores and memory, too) can be added easily when available.
As a rule of thumb, we should use shared memory when we have a computer with a lot of cores, and distributed memory when we have a cluster consisting of several compute nodes.
Hybrid Parallel Computing
When looking at how the processor market is developing, we can see the clear trend that the processors are no longer gaining performance by increasing the clock frequency, but are rather equipped with more and more cores. The first x86 dual core processor was released by AMD in 2004. During the latter half of 2013, Intel released a processor with 12 cores, and if we are to believe the rumors, the Knights Landing technology from Intel could feature 72 cores!
This also means that clusters with single-core compute nodes are an outdated rarity. The majority of the clusters in the TOP500 list have compute nodes equipped with eight cores per socket. A similar set-up applies to small- and medium-sized compute clusters. These widespread configurations make it inevitable that we exploit both shared memory mechanisms for intranode computations and distributed memory mechanisms for internode computations at the same time. The goal hereby is to maximize scalability, minimize the costly message passing overhead, and utilize the power of shared memory in a unified approach called hybrid parallel computing. The combination of shared and distributed memory mechanisms in a hybrid method provides a versatile means to adapt to all kinds of computing platforms. Choosing the right way to combine the two ways of parallelization will speed up computations, increase scalability, and allow efficient utilization of the hardware.
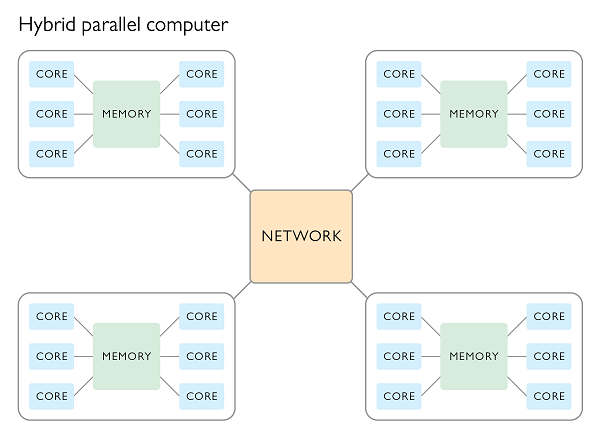
COMSOL Software and Hybrid Parallelization
By default, when you start COMSOL® software on a multicore-parallel workstation or PC, all available cores are used to parallelize the computations by means of the shared memory approach. When working on a workstation or on a cluster, you as a user can control how the parallelization is applied. You can choose whether you want to run it in the distributed memory mode, in the shared memory mode, or in the hybrid mode. You can find a detailed description of how to do this in the COMSOL reference manual.
COMSOL Multiphysics® and its add-on products are tailored for computing coupled physics. The way of choosing the optimal parallel configurations very much depends on the underlying physics, the level of couplings in the model, the problem size, and the choice of the solver. The fine-grained controls that are provided for you make it possible to find the best parallel configurations of the COMSOL software for your problem.


Comments (0)