

Little-known functionality of the Study node is its ability to perform a programmatic sequence of operations, including solving; saving the model to file; and generating and exporting plot groups, results, and images. In this blog post, we take a closer look at this capability. If you use the COMSOL Multiphysics® software, there is a good chance you will find this information useful in your modeling work.
Example: Micromixer Model
To demonstrate this functionality, we will first load the Micromixer tutorial model from the Application Libraries. This model is available in the folder COMSOL Multiphysics > Fluid Dynamics and illustrates fluid flow and mass transport in a laminar static mixer.
The model performs a fluid flow simulation using a Laminar Flow interface. In the next step, it shows how to calculate the mixing efficiency by means of a Transport of Diluted Species interface, using the results from the fluid flow simulation as input. The species will be transported downstream based on the fluid velocity.
The computation time for this model is a few minutes. To simplify the model a bit so that we can run the computation quicker, we won’t solve for the species transport. To achieve this, we will make one modification to the Settings window of the second study step, Step 2: Stationary 2, by clearing the Transport of Diluted Species check box.
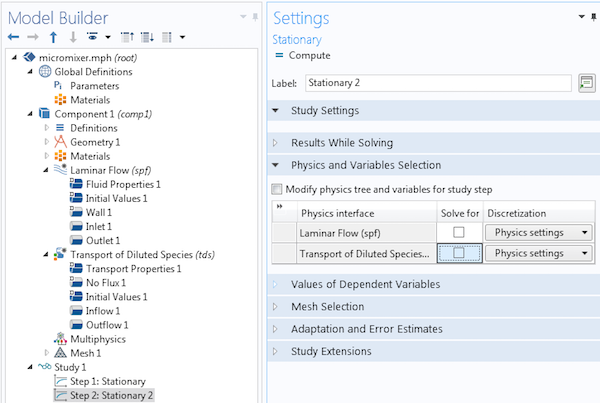
We can make an additional change to the model in order for it to run faster. Set the Sequence type for the mesh to Physics-controlled mesh and the element size to Extremely coarse.
Now, we can compute Study 1 to make sure everything works. The resulting plot shows the velocity magnitude at a few slices along the mixer geometry.

Using Job Sequences to Save Data
Here, we will focus our attention on one important part of a job configuration: the Sequence option.
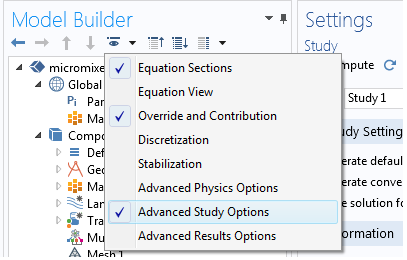
To be able to define a sequence of operations under the Study node, we enable Advanced Study Options. This is an available menu option under the Model Builder toolbar. Click the “eye” symbol to see the menu.
Enabling this setting reveals a hidden Job Configurations node in the model tree. This node is something that you don’t need to worry about during conventional modeling work. It essentially stores low-level information pertaining to the order in which the solution process should be run. Normally, this is controlled indirectly from the top level of a study without the need for enabling Advanced Study Options.
Right-click Job Configurations and select Sequence.
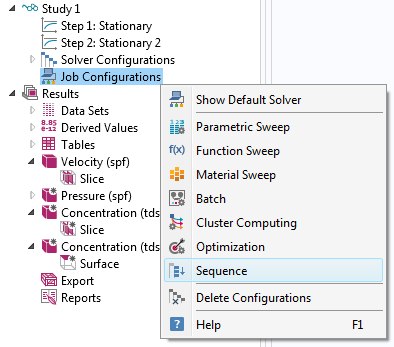
Next, right-click Sequence to see, below the Run option, a variety of options that can be added as an ordered sequence of operations performed when running the sequence:
- Job
- Solution
- Other
- Save Model to File
- Results
Job refers to another sequence that is to be run from this sequence, while Solution runs a Solution node as available under the Solver Configurations node, available further up in the Study tree.
Under Other, you can choose External Class, which calls an external Java® class file. Another option, Geometry, builds the Geometry node. This can be used, for example, in combination with a parametric sweep to generate a sequence of MPH-files with different geometry parameters. The Mesh option builds the Mesh node.
Save Model to File saves the solved model to an MPH-file.
Under the Results option, you can choose Plot Group to run all or a selected set of plot groups. This is useful to automate the generation of plot groups after solving. You also don’t have to manually click through all of the plot groups to generate the corresponding visualizations. The Derived Value option is there for legacy reasons and we recommend that you use the Evaluate Derived Values option, which will evaluate nodes under Results > Derived Values. The option Export to File runs any node for data export under the Export node.
Let’s now create a simple sequence. Right-click the Sequence node and select Solution.
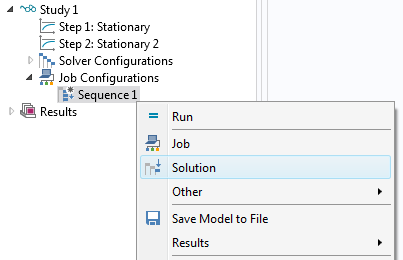
The default option for a Solution node in a sequence is to run all solution nodes. The Run option in the General section lets you specify which Solution data structures should be computed. The Solution data structures are available as child nodes, together with other nodes, under Solver configurations. They can be recognized by their short name written within parentheses, such as (sol1) and (sol2). The solution data structures are low-level representations of the solutions.
In this example, you can keep the default All for the Solution data structures.
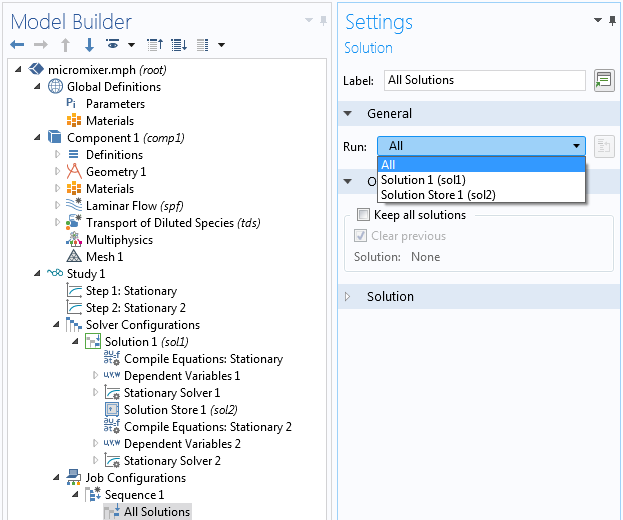
We would like to save the file when the solver is finished. Right-click the Sequence node and select Save Model to File.
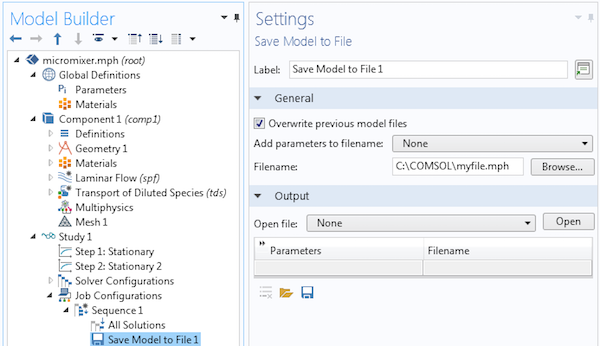
In the Settings window, you can see a number of options that are related to the capability of saving a series of MPH-files with parameters added at the end of the file name. This is very useful for parametric sweeps such as batch sweeps. However, we will not need to do this in such a simple example, so we change the option Add parameters to filename to None. At this stage, we also need to give a file name to a location where we have permission to write. In this example, the file name and path is C:\COMSOL\myfile.mph.
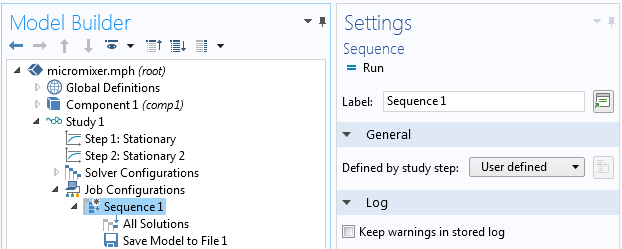
To run these operations, select the Sequence node and click Run.
Writing Data to File After Solving in COMSOL Multiphysics®
The library model that we started from already has one defined derived value. You can see this under Results > Derived Values > Global Evaluation. The variable is called S_outlet and is the relative concentration variance at the outlet. It is defined as a variable under Component > Definitions > Variables.
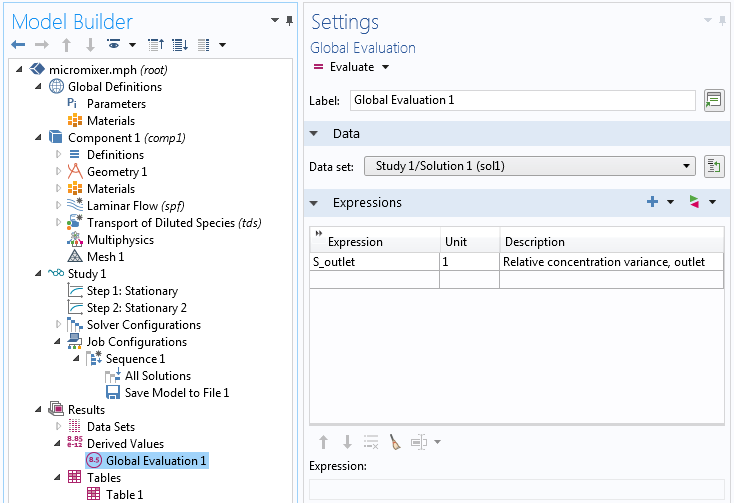
The value of S_outlet is sent to Table 1. We can choose to store this value on file by changing a setting in the Settings window of Table 1. Change Store table to On file and type a file name; for example, C:\COMSOL\my_data.txt.
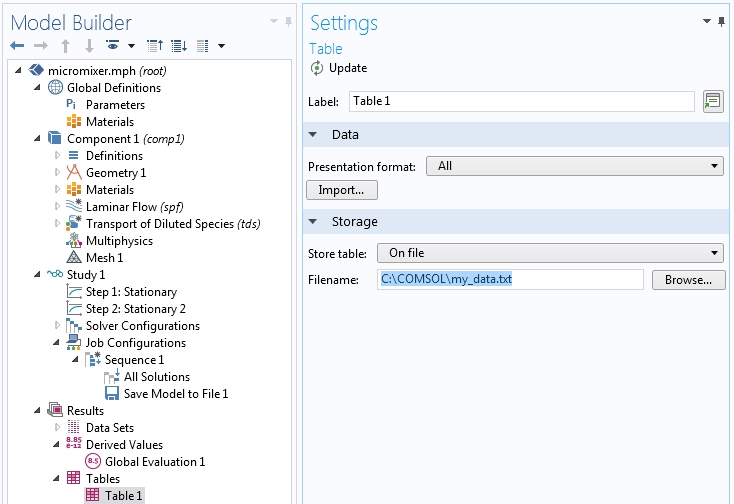
Now, add an Evaluate Derived Values operation to the sequence.
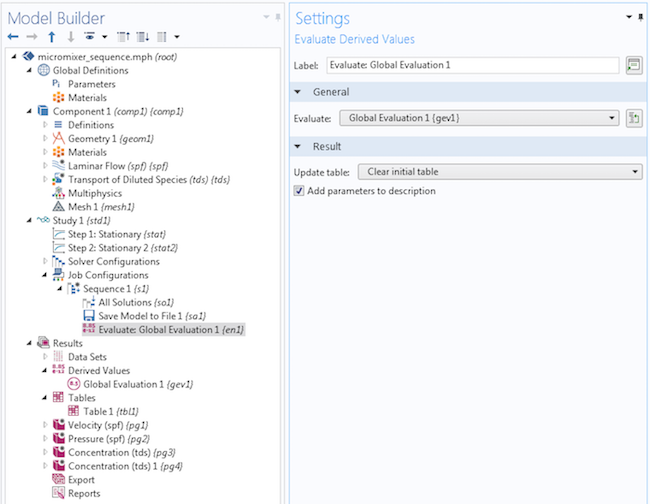
In the General section, you can change the Evaluate setting to Global Evaluation 1. However, in this simple example model, you can omit this step. Note that the name of the node in the model tree changes to Evaluate: Global Evaluation 1.
You can now run the sequence again. However, for this last step to make sense, you need to enable the Transport of Diluted Species interface in the Settings window for Step 2: Stationary 2.
Running Job Sequences from the Command Line
If you want to run a job sequence from the command line in the Windows® or Linux® operating systems, or macOS, you cannot use the method shown above, but instead you need to add a parametric sweep with a dummy parameter. However, if you were already running a parametric sweep, then all you need to know is that a parametric sweep is just a special type of job sequence and then follow the instructions above, but with a Job Configurations>Parametric Sweep node replacing a Job Configurations>Sequence node.
The reason for this is historical and reflects the evolution of the Study node functionality over time. The operating system command interface doesn’t let you run any part of a Study node that is not controlled at the top level of the Study node. You can only specify which study to run, for example, in the Linux® operating system:
comsol batch -inputfile mymodel.mph -study std1
for Study 1 with tag std1.
You cannot run a sequence in this way, since the top-level study step is unaware of your edits under the Job Configuration node. To make the study step at the top of the Study node tree “aware” of your edits under the Job Configurations node, the easiest way is to add a parametric sweep with an arbitrary parameter defined under Global Definitions > Parameters; say, dummy with value 1. Sweeping over this parameter then adds the extra overhead needed to get a handle on the Job Configuration node from the top level of the Study node. Then, you can issue a command-line batch command to run it.
This is how the corresponding “dummy” sweep will look:
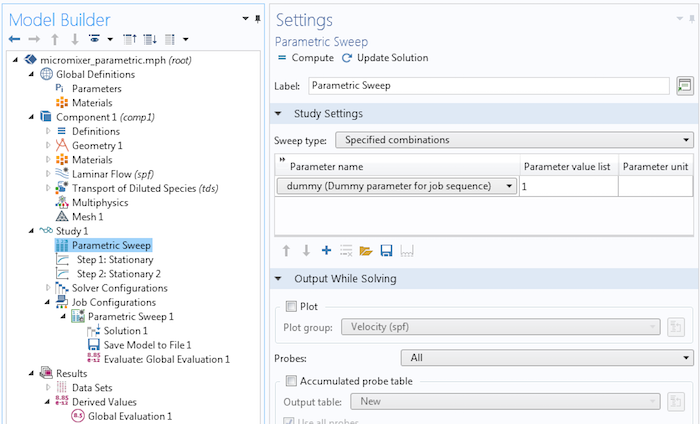
The following figure shows the corresponding sweep over one parameter value for the dummy parameter.
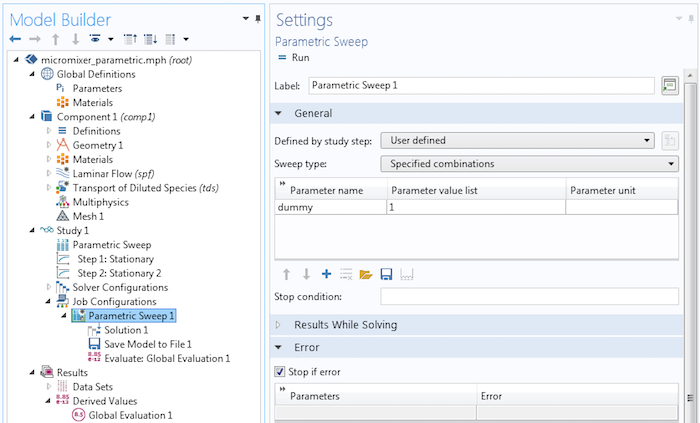
Now, knowing that the Parametric Sweep 1 node is just a special type of Sequence node, the child nodes Solution 1, Save Model to File 1, and Evaluate: Global Evaluation 1 are just as they are in the example above using Sequence.
Enable the display of model tree tags by selecting Tag from the Model Tree Node Text menu, available in the Model Builder toolbar.
The study tag std1 is now visible in the model tree:
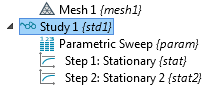
The Linux® command shown earlier will now run the sequence of operations that solves, saves the model to file, and finally evaluates the Global Evaluation node. Note that if you only have one Study node in your model, then you can skip the input argument study std1.
Note that if you already have a parametric sweep in your model, these can be of two types loosely referred to as “inner sweep” and “outer sweep”. The sweep in the example above using the dummy parameter is an “outer sweep”. The Study node will autodetect which type of sweep to use for best performance, but you can take control manually, if needed. In order to use a job sequence from the command line, your sweep needs to be an “outer sweep”.
More or less all types of sweeps can be changed from being an inner sweep to an outer sweep, but not the other way around. Inner sweeps can be faster, since they will use some of the underlying structure of the computation to speed things up. However, not all types of sweeps can be inner sweeps. For example, a sweep over a geometry parameter always needs to be an outer sweep; again, this is handled automatically by the solver. To make sure the parameter sweep is an outer sweep, change the Use parametric solver to Off in the Parametric Sweep settings, then perform a Show default solver operation and continue from there.
Summary
Job sequences can be used to automate a number of common tasks after solving a model. In this blog post, we have seen examples of:
- Saving the model to file as an MPH-file after solving
- Exporting Derived Values to file automatically after solving
There are other tasks that use job sequences that you can try on your own, including:
- Regenerating all plots after solving
- Exporting plot data to file
- Exporting image data to file
We hope you find that job sequences are a useful feature for your everyday modeling work!
Oracle and Java are registered trademarks of Oracle and/or its affiliates. Microsoft and Windows are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. Linux is a registered trademark of Linus Torvalds in the U.S. and other countries. macOS is a trademark of Apple Inc., registered in the U.S. and other countries.


Comments (4)
Daniele Stefanini
June 23, 2017Good morning,
very good post, exactly what I was looking for and even more simple than using an App or writing Java code….thank you !
With this method I can run simulations over night and find the job fully completed the day after
Daniele
Bjorn Sjodin
June 23, 2017Hi Daniele,
Good to hear that you found it useful.
Best regards,
Bjorn
Daniele Stefanini
August 23, 2017I have a question.
I have multiple files, which I want to launch by using a comsolbatch .bat file.
For each file, I would like to perform the Sequence (there is only one…) included within “Job Configuration”
The Sequence is doing following things :
– solve the problem
– store the file
– plot all
– export all
Is there any argument I can use in the comsolbatch to perform this operation ?
Thanks,
Daniele
Bjorn Sjodin
August 23, 2017Hi Daniele,
This can be done by first enabling Advanced Study Options and then adding a Batch job node under Job Configurations. The Batch job node is very similar to a Sequence so you can then add your desired sequence of commands under Batch instead of under Sequence. Then call the comsolbatch command with the additional argument -job b1
where b1 is the “tag” of the Batch sequence. You can see this tag displayed in the Properties window (to see it, right-click and select Properties).
The details of how you would do this depend on the exact nature of what you are trying to achieve. I suggest that you contact our support team for further assistance since the details can become quite specific to your model.
Best regards,
Bjorn